



Ново многоезично проучване, което оценява как големите езикови модели обработват дълги документи, доведе до неочаквана информация: полският, а не английският или китайският показва най-висока точност, когато контекстните прозорци се разширяват до 64 000 токена и повече. Резултатите са от бенчмарка OneRuler, представен в статия на COLM 2025, в която са тествани 26 езика в задачи за извличане и агрегиране.
Изследователите сравниха точността на моделите при различни дължини на контекста и откриха ясна промяна, когато последователностите станаха по-дълги. Според диаграмата с резултатите полският език води пред всички езици със средна точност от 88% при дълги контексти. Английският език спада на шесто място, а китайският се нарежда сред последните четири.
Проучването подсказва, че разликата може да е свързана с ефективността на токенизацията и разликите в азбуките, а не просто с обема на данните за обучение. Езиците, които използват латинска азбука – като полски, френски и испански, – постигат по-добри резултати от тези, които използват логографски или абугида писмени системи. Китайски, корейски, тамилски и други езици показват само умерена точност дори при по-къси контексти (а точността им се влошава още повече с удължаването на последователностите). Това пълно обръщане на очакваните класификации е интересно, защото повечето широкоразпространени LLM са обучени предимно на бази данни с преобладаващ английски език. Резултатите от статията обаче показват, че когато моделите трябва да търсят, извличат или обобщават информация, скрита дълбоко в дълги документи, структурните аспекти на езика имат предимство пред преобладаването на базите данни.
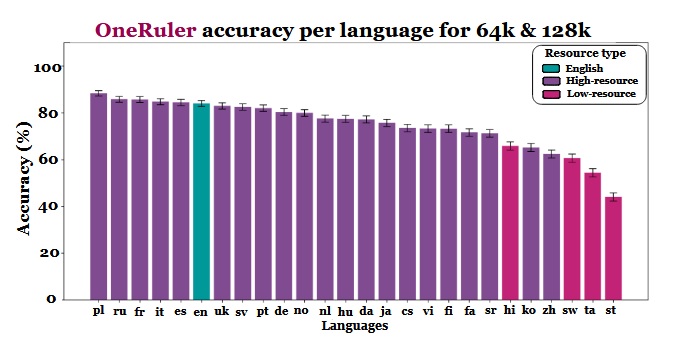
Други констатации в бенчмарка също подкрепят тази интерпретация. Разликата в представянето между най-силните и най-слабите езици нараства рязко с разширяването на контекста – от 11% при 8000 токена до 34% при 128 000 токена. Друга подробност от проучването показва колко чувствителни могат да бъдат тези тестове към малки промени в инструкциите. Например простото позволяване на модела да отговори „няма“ при липса на целева низове, доведе до спад в точността на английския език с 32% при 128 000 токена, както е видно на страница 2.
Макар че бенчмаркът сравнява и семейства модели, резултатите показват, че оценката на дългия контекст не може да се основава единствено на тестове на английски език и че обобщенията за представянето на различните езици могат да бъдат подвеждащи, ако се пренебрегнат ефектите от скрипта и токенизацията. С разширяването на контекстните прозорци езиковите разлики стават по-важни, а не по-малко важни – и доминирането на английския език в LLM бенчмарковете може да престане да бъде представително, когато дължината на последователностите достигне десетки хиляди.
Снимка: Pexels/COLM 2025
Виж още: Този човек използва 1000 батерии от лаптоп, за да захранва дома си независимо вече цели 8 години
Още по темата
Коментари (0)








Още от Tech


Препоръчано





Може Да Харесате




Избрано от редактора
Селекция от статии и ревюта от редакторите на HiComm




