


–Р–Ї–Њ –Є–Ј–Ї—Г—Б—В–≤–µ–љ–Є—П—В –Є–љ—В–µ–ї–µ–Ї—В –µ —З–∞—Б—В –Њ—В —Б—К–≤—А–µ–Љ–µ–љ–љ–∞—В–∞ –Є—Б—В–Њ—А–Є—П, —В–Њ –і–∞–ї–Є –µ –≤—К–Ј–Љ–Њ–ґ–љ–Њ —В–Њ–є –і–∞ –љ–Є –њ–Њ–Љ–Њ–≥–љ–µ –і–∞ –Є–Ј—П—Б–љ–Є–Љ –љ—П–Ї–Њ–Є –љ–µ–Є–Ј–≤–µ—Б—В–љ–Є –Њ—В –Љ–Є–љ–∞–ї–Њ—В–Њ? –Т–µ—З–µ —Б–Љ–µ –≤–Є–ґ–і–∞–ї–Є —З—А–µ–Ј –љ–µ–≥–Њ –і–∞ –±—К–і–∞—В –Ј–∞–≤—К—А—И–≤–∞–љ–Є –Ї–∞—А—В–Є–љ–Є –Є–ї–Є –і–∞ –±—К–і–∞—В —А–∞–Ј–њ–Њ–Ј–љ–∞–≤–∞–љ–Є —Д–∞–ї—И–Є—Д–Є–Ї–∞—В–Є –Њ—В –Њ—А–Є–≥–Є–љ–∞–ї–Є, —В–∞–Ї–∞ —З–µ –Ї–∞–Ї–≤–∞ –µ —Б–ї–µ–і–≤–∞—Й–∞—В–∞ —Б—В—К–њ–Ї–∞?
Google DeepMind –≤ —Б—К—В—А—Г–і–љ–Є—З–µ—Б—В–≤–Њ —Б –µ–Ї–Є–њ —Г—З–µ–љ–Є —Б—К–Ј–і–∞–і–µ –љ–Њ–≤ –Є–љ—Б—В—А—Г–Љ–µ–љ—В, –±–∞–Ј–Є—А–∞–љ –љ–∞ –Є–Ј–Ї—Г—Б—В–≤–µ–љ –Є–љ—В–µ–ї–µ–Ї—В, –Ї–Њ–є—В–Њ –Є–Ј–њ–Њ–ї–Ј–≤–∞ –і—К–ї–±–Њ–Ї–Є –љ–µ–≤—А–Њ–љ–љ–Є –Љ—А–µ–ґ–Є –Ј–∞ –і–µ—И–Є—Д—А–Є—А–∞–љ–µ –љ–∞ –њ–Њ–≤—А–µ–і–µ–љ–Є —В–µ–Ї—Б—В–Њ–≤–µ –Њ—В –Ф—А–µ–≤–љ–∞ –У—К—А—Ж–Є—П. –Э–Њ–≤–∞—В–∞ —Б–Є—Б—В–µ–Љ–∞ –љ–Њ—Б–Є –Є–Љ–µ—В–Њ Ithaca –Є —Б–µ –Њ—Б–љ–Њ–≤–∞–≤–∞ –љ–∞ –њ–Њ-—А–∞–љ–љ–∞ —Б–Є—Б—В–µ–Љ–∞ –Ј–∞ –≤—К–Ј—Б—В–∞–љ–Њ–≤—П–≤–∞–љ–µ –љ–∞ —В–µ–Ї—Б—В, –љ–∞—А–µ—З–µ–љ–∞ Pythia. –°–њ–Њ—А–µ–і –њ—А–Њ—Г—З–≤–∞–љ–µ, –њ—Г–±–ї–Є–Ї—Г–≤–∞–љ–Њ –≤ —Б–њ. Nature, Ithaca –Є–і–µ–љ—В–Є—Д–Є—Ж–Є—А–∞ –љ–µ —Б–∞–Љ–Њ —В–µ–Ї—Б—В–∞, –љ–Њ –Є –њ—А–Њ–Є–Ј—Е–Њ–і–∞ –Љ—Г –Є –њ—А–∞–≤–Є –њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є–µ –Ј–∞ –≤—А–µ–Љ–µ—В–Њ –љ–∞ —Б—К–Ј–і–∞–≤–∞–љ–µ—В–Њ –Љ—Г. –Т –і–µ–є—Б—В–≤–Є—В–µ–ї–љ–Њ—Б—В, –Љ–љ–Њ–≥–Њ –Њ—В –Є–Ј—В–Њ—З–љ–Є—Ж–Є—В–µ - –љ–µ–Ј–∞–≤–Є—Б–Є–Љ–Њ –і–∞–ї–Є —Б—В–∞–≤–∞ –≤—К–њ—А–Њ—Б –Ј–∞ —Б–≤–Є—В—К—Ж–Є, –њ–∞–њ–Є—А—Г—Б–Є, –Ї–∞–Љ—К–Ї, –Љ–µ—В–∞–ї –Є–ї–Є –Ї–µ—А–∞–Љ–Є–Ї–∞ - —Б–∞ —В–Њ–ї–Ї–Њ–≤–∞ –њ–Њ–≤—А–µ–і–µ–љ–Є, —З–µ –≥–Њ–ї—П–Љ–∞ —З–∞—Б—В –Њ—В —В—П—Е —Б–∞ –њ—А–∞–Ї—В–Є—З–µ—Б–Ї–Є –љ–µ—З–µ—В–Є–Љ–Є. –Ю–њ—А–µ–і–µ–ї—П–љ–µ—В–Њ –љ–∞ –Љ—П—Б—В–Њ—В–Њ –љ–∞ –њ—А–Њ–Є–Ј—Е–Њ–і –љ–∞ —В–µ–Ї—Б—В–Њ–≤–µ—В–µ —Б—К—Й–Њ –Љ–Њ–ґ–µ –і–∞ –±—К–і–µ –њ—А–µ–і–Є–Ј–≤–Є–Ї–∞—В–µ–ї—Б—В–≤–Њ, —В—К–є –Ї–∞—В–Њ —В–µ –≤–µ—А–Њ—П—В–љ–Њ —Б–∞ –±–Є–ї–Є –њ—А–µ–Љ–µ—Б—В–≤–∞–љ–Є –Љ–љ–Њ–≥–Њ–Ї—А–∞—В–љ–Њ. –Ш–і–µ–љ—В–Є—Д–Є—Ж–Є—А–∞–љ–µ—В–Њ –љ–∞ –µ–њ–Њ—Е–∞—В–∞ –Є–Љ —Б—К—Й–Њ –µ –≥–Њ–ї—П–Љ–Њ –њ—А–µ–і–Є–Ј–≤–Є–Ї–∞—В–µ–ї—Б—В–≤–Њ, –њ–Њ–љ–µ–ґ–µ —Б—В–∞–љ–і–∞—А—В–љ–Є—В–µ –Љ–µ—В–Њ–і–Є –љ–µ —Б–∞ –Њ—Б–Њ–±–µ–љ–Њ —Й–∞–і—П—Й–Є –Ї—К–Љ –∞—А—В–µ—Д–∞–Ї—В–Є—В–µ. –°–њ–µ—Ж–Є–∞–ї–Є—Б—В–Є—В–µ —Б–Љ—П—В–∞—В, —З–µ –Љ–љ–Њ–≥–Њ —З–µ—Б—В–Њ –Љ–Њ–ґ–µ –і–∞ –Є–Љ–∞ –љ—П–Ї–Њ–ї–Ї–Њ –≤—К–Ј–Љ–Њ–ґ–љ–Є —В—А–∞–Ї—В–Њ–≤–Ї–Є, –Ї–∞—В–Њ —З–µ—Б—В–Њ —Б–µ —А–∞–Ј—З–Є—В–∞ –љ–∞ –Є–≥—А–Є —Б –і—Г–Љ–Є—В–µ –Є –Њ—В–≥–∞—В–≤–∞–љ–µ –љ–∞ –ї–Є–њ—Б–≤–∞—Й–Є—В–µ —Б–Є–Љ–≤–Њ–ї–Є, –Ї–Њ–Є—В–Њ –і–∞ –Ј–∞–≤—К—А—И–∞—В —Д—А–∞–Ј–∞—В–∞. –†–∞–Ј–±–Є—А–∞ —Б–µ, —А–∞–Ј—З–Є—В–∞ –Є –љ–∞ –і—А—Г–≥–Є –Ї–Њ–љ—В–µ–Ї—Б—В–љ–Є —Г–ї–Є–Ї–Є –≤ –љ–∞–і–њ–Є—Б–∞ - –Ї–∞—В–Њ –≥—А–∞–Љ–∞—В–Є—З–µ—Б–Ї–Є –Є –µ–Ј–Є–Ї–Њ–≤–Є —Б—К–Њ–±—А–∞–ґ–µ–љ–Є—П, –Њ—Д–Њ—А–Љ–ї–µ–љ–Є–µ –Є —Д–Њ—А–Љ–∞, —В–µ–Ї—Б—В–Њ–≤–Є –Є –Є—Б—В–Њ—А–Є—З–µ—Б–Ї–Є –њ–∞—А–∞–ї–µ–ї–Є.

–Ъ–∞–Ї—В–Њ –≤–µ—З–µ —Г—В–Њ—З–љ–Є—Е–Љ–µ, –њ—К—А–≤–Њ–љ–∞—З–∞–ї–љ–Њ –±–µ—И–µ —А–∞–Ј—А–∞–±–Њ—В–µ–љ–∞ Pythia, —Б–Є—Б—В–µ–Љ–∞ –Ј–∞ –≤—К–Ј—Б—В–∞–љ–Њ–≤—П–≤–∞–љ–µ –љ–∞ –і—А–µ–≤–µ–љ —В–µ–Ї—Б—В, –љ–∞—А–µ—З–µ–љ–∞ –љ–∞ –Є–Љ–µ—В–Њ –љ–∞ –≤—К—А—Е–Њ–≤–љ–∞—В–∞ –ґ—А–Є—Ж–∞, –Ї–Њ—П—В–Њ –µ –Ї–∞—В–Њ –Ф–µ–ї—Д–Є–є—Б–Ї–Є –Њ—А–∞–Ї—Г–ї, –Ї–Њ–є—В–Њ –і–Њ—Б—В–∞–≤—П –Є–Ј—П–≤–ї–µ–љ–Є—П –љ–∞ –±–Њ–≥ –Р–њ–Њ–ї–Њ–љ. Pythia –±–µ—И–µ –і–µ–ї–Њ –љ–∞ –ѓ–љ–Є—Б –Р—Б–∞–µ–ї, –Ґ–µ–∞ –°–Њ–Љ—К—А—И–Є–ї–і –Є –Ф–ґ–Њ–љ–∞—В–∞–љ –Я—А–∞–≥ –Њ—В DeepMind, –Ї–Њ–Є—В–Њ —Б–Є —Б—К—В—А—Г–і–љ–Є—З–Є—Е–∞ —Б –Є–Ј—Б–ї–µ–і–Њ–≤–∞—В–µ–ї–Є –Њ—В –Ю–Ї—Б—Д–Њ—А–і—Б–Ї–Є—П —Г–љ–Є–≤–µ—А—Б–Є—В–µ—В. –Ч–∞ –і–∞ “–Ј–∞—Е—А–∞–љ—П—В” —Б–Є—Б—В–µ–Љ–∞—В–∞, –љ–∞–і 35 000 –љ–∞–і–њ–Є—Б–∞ –Є –њ–Њ–≤–µ—З–µ –Њ—В 3 –Љ–Є–ї–Є–Њ–љ–∞ –і—Г–Љ–Є –Њ—В VII –≤–µ–Ї –њ—А.–љ.–µ. –і–Њ V –≤–µ–Ї –љ.–µ., —Б—К–і—К—А–ґ–∞—Й–Є —Б–µ –≤ –±–∞–Ј–∞—В–∞ –і–∞–љ–љ–Є –љ–∞ Packard Humanities Institute (PHI), –±—П—Е–∞ —В—А–∞–љ—Б—Д–Њ—А–Љ–Є—А–∞–љ–Є –≤ —В–µ–Ї—Б—В —Б –Љ–∞—И–Є–љ–љ–Њ –і–µ–є—Б—В–≤–Є–µ, –Ї–Њ–є—В–Њ —В–µ –љ–∞—А–µ–Ї–Њ—Е–∞ PHI-ML. –°–ї–µ–і —В–Њ–≤–∞ Pythia –±–µ—И–µ –Њ–±—Г—З–µ–љ–∞ –і–∞ –њ—А–µ–і—Б–Ї–∞–Ј–≤–∞ –ї–Є–њ—Б–≤–∞—Й–Є—В–µ –і—Г–Љ–Є –Є –Ј–љ–∞—Ж–Є –±–ї–∞–≥–Њ–і–∞—А–µ–љ–Є–µ –љ–∞ –≤—К–Ј–Љ–Њ–ґ–љ–Њ—Б—В–Є—В–µ –љ–∞ –і—К–ї–±–Њ–Ї–Є –љ–µ–≤—А–Њ–љ–љ–Є –Љ—А–µ–ґ–Є. –°–Є—Б—В–µ–Љ–∞—В–∞ –Љ–Њ–ґ–µ—И–µ –і–∞ –≤—К–Ј–њ—А–Њ–Є–Ј–≤–µ–і–µ –і–Њ 20 —А–∞–Ј–ї–Є—З–љ–Є –≤—К–Ј–Љ–Њ–ґ–љ–Є –±—Г–Ї–≤–Є –Є–ї–Є –і—Г–Љ–Є, –Ї–Њ–Є—В–Њ –±–Є—Е–∞ –Љ–Њ–≥–ї–Є –і–∞ –Ј–∞–њ—К–ї–љ—П—В –њ—А–Њ–њ—Г—Б–Ї–Є—В–µ, –љ–Њ –Њ—В —Б–∞–Љ–Є—В–µ –Є—Б—В–Њ—А–Є—Ж–Є –Ј–∞–≤–Є—Б–µ—И–µ –Ї–Њ–є –≤–∞—А–Є–∞–љ—В –µ –љ–∞–є-—Г–і–∞—З–µ–љ.
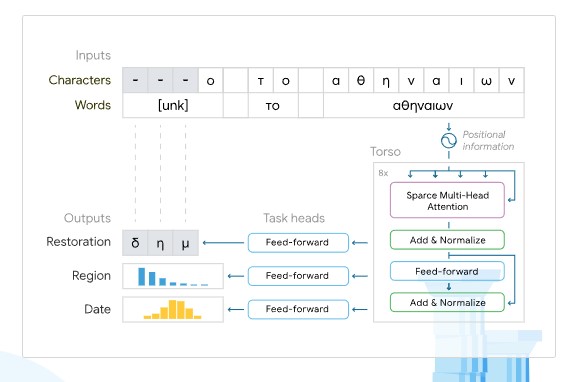
–°–µ–≥–∞ –µ–Ї–Є–њ—К—В —Б–µ –Ј–∞–≤—А—К—Й–∞ —Б Ithaca, –Ї–Њ—П—В–Њ –Љ–Њ–ґ–µ –і–∞ “—Е–≤—К—А–ї–Є —Б–≤–µ—В–ї–Є–љ–∞ –≤—К—А—Е—Г –≤—К–Ј–Љ–Њ–ґ–љ–Є—В–µ –Њ—Б–љ–Њ–≤–љ–Є –≥–µ–Њ–≥—А–∞—Д—Б–Ї–Є –≤—А—К–Ј–Ї–Є –≤ –і—А–µ–≤–љ–Є—П —Б–≤—П—В” –Љ–µ–ґ–і—Г 800 –≥. –њ—А.–љ.–µ. –Є 800 –≥. –љ.–µ. –Ґ–µ—Б—В–≤–∞–љ–µ—В–Њ —А–∞–Ј–Ї—А–Є, —З–µ Ithaca —Б–∞–Љ–∞ –њ–Њ —Б–µ–±–µ —Б–Є –µ –≤ —Б—К—Б—В–Њ—П–љ–Є–µ –і–∞ –њ–Њ—Б—В–Є–≥–љ–µ 62 –њ—А–Њ—Ж–µ–љ—В–∞ —В–Њ—З–љ–Њ—Б—В –њ—А–Є –≤—К–Ј—Б—В–∞–љ–Њ–≤—П–≤–∞–љ–µ—В–Њ –љ–∞ –њ–Њ–≤—А–µ–і–µ–љ —В–µ–Ї—Б—В –≤ —Б—А–∞–≤–љ–µ–љ–Є–µ —Б 25 –њ—А–Њ—Ж–µ–љ—В–∞ —В–Њ—З–љ–Њ—Б—В, –њ–Њ—Б—В–Є–≥–љ–∞—В–∞ –Њ—В —Б–∞–Љ–Є—В–µ –Є—Б—В–Њ—А–Є—Ж–Є. –Э–Њ –Ї–Њ–Љ–±–Є–љ–∞—Ж–Є—П—В–∞ –Њ—В —З–Њ–≤–µ–Ї –Є –Љ–∞—И–Є–љ–∞ –њ–Њ–≤–Є—И–∞–≤–∞ –Њ–±—Й–∞—В–∞ —В–Њ—З–љ–Њ—Б—В –і–Њ 72 –њ—А–Њ—Ж–µ–љ—В–∞, –Ї–Њ–µ—В–Њ –µ –µ–і–љ–Њ –љ–∞–Є—Б—В–Є–љ–∞ –µ–Љ–±–ї–µ–Љ–∞—В–Є—З–љ–Њ –њ–Њ—Б—В–Є–ґ–µ–љ–Є–µ. Ithaca –≤–µ—З–µ –µ –±–Є–ї–∞ –њ–Њ—Б—В–∞–≤–µ–љ–∞ –љ–∞ —В–µ—Б—В –Њ—В–љ–Њ—Б–љ–Њ –њ—А–∞–≤–Є–ї–љ–Є—В–µ –і–∞—В–Є –љ–∞ –≥—А—Г–њ–∞ –і—А–µ–≤–љ–Є –Р—В–Є–љ—Б–Ї–Є –і–µ–Ї—А–µ—В–Є, –Ї–Њ–Є—В–Њ —Б–∞ –±–Є–ї–Є –Њ–±–µ–Ї—В –љ–∞ –Є—Б—В–Њ—А–Є—З–µ—Б–Ї–Є —Б–њ–Њ—А: –Є—Б—В–Њ—А–Є—Ж–Є—В–µ —Б–∞ —Б–Љ—П—В–∞–ї–Є, —З–µ —В–µ –і–∞—В–Є—А–∞—В –љ–µ –њ–Њ-–Ї—К—Б–љ–Њ –Њ—В 446 –≥. –њ—А.–љ.–µ., –љ–Њ –љ—П–Ї–Њ–Є –Є—Б—В–Њ—А–Є—Ж–Є –Ј–∞–њ–Њ—З–љ–∞—Е–∞ –і–∞ –њ–Њ—Б—В–∞–≤—П—В –њ–Њ–і –≤—К–њ—А–Њ—Б —В–Њ–Ј–Є –њ–µ—А–Є–Њ–і, –Њ—Б–Њ–±–µ–љ–Њ —Б–ї–µ–і –Ї–∞—В–Њ –љ—П–Ї–Њ–Є –Њ—В —В—П—Е –Є–Ј–њ–∞–і–љ–∞—Е–∞ –≤ –њ—А–µ–і–њ–Њ–ї–∞–≥–∞–µ–Љ–Њ –њ—А–Њ—В–Є–≤–Њ—А–µ—З–Є–µ —Б –Є—Б—В–Њ—А–Є—З–µ—Б–Ї–Є—В–µ —А–∞–Ј–Ї–∞–Ј–Є –љ–∞ –Ґ—Г–Ї–Є–і–Є–і. –°–њ–Њ—А–µ–і Ithaca —В–µ —Б–µ –і–∞—В–Є—А–∞—В –Њ—В 421 –≥. –њ—А.–љ.–µ., –Ї–Њ–µ—В–Њ –µ –Љ–љ–Њ–≥–Њ –±–ї–Є–Ј–Ї–Њ –Є –і–Њ —Б—К–≤—А–µ–Љ–µ–љ–љ–Њ—В–Њ –њ—А–µ–і–њ–Њ–ї–Њ–ґ–µ–љ–Є–µ –љ–∞ –Є—Б—В–Њ—А–Є—Ж–Є—В–µ. „–Т—К–њ—А–µ–Ї–Є —З–µ –Љ–Њ–ґ–µ –і–∞ –Є–Ј–≥–ї–µ–ґ–і–∞ –Ї–∞—В–Њ –Љ–∞–ї–Ї–∞ —А–∞–Ј–ї–Є–Ї–∞, —В–∞–Ј–Є –њ—А–Њ–Љ—П–љ–∞ –љ–∞ –і–∞—В–∞—В–∞ –Є–Љ–∞ –Ј–љ–∞—З–Є—В–µ–ї–љ–Є –њ–Њ—Б–ї–µ–і–Є—Ж–Є –Ј–∞ –љ–∞—И–µ—В–Њ —А–∞–Ј–±–Є—А–∞–љ–µ –Ј–∞ –њ–Њ–ї–Є—В–Є—З–µ—Б–Ї–∞—В–∞ –Є—Б—В–Њ—А–Є—П –љ–∞ –Ї–ї–∞—Б–Є—З–µ—Б–Ї–∞ –Р—В–Є–љ–∞“, –Ї–∞–Ј–∞ –°–Њ–Љ—К—А—И–Є–ї–і –≤ –Є–Ј—П–≤–ї–µ–љ–Є–µ. –°–њ–Њ—А–µ–і –µ–Ї–Є–њ–∞ —Б–ї–µ–і–≤–∞—Й–∞—В–∞ —Б—В—К–њ–Ї–∞ –µ –і–∞ —Б–µ —А–∞–Ј—А–∞–±–Њ—В—П—В –і–Њ–њ—К–ї–љ–Є—В–µ–ї–љ–Є –≤–µ—А—Б–Є–Є –љ–∞ Ithaca, –Ї–Њ–Є—В–Њ –Љ–Њ–≥–∞—В –і–∞ –≤—К–Ј—Б—В–∞–љ–Њ–≤—П—В —В–µ–Ї—Б—В –љ–∞ –і—А—Г–≥–Є –і—А–µ–≤–љ–Є –µ–Ј–Є—Ж–Є, –≤–Ї–ї—О—З–Є—В–µ–ї–љ–Њ –∞–Ї–∞–і—Б–Ї–Є, –і–µ–Љ–Њ—В—Б–Ї–Є, –Є–≤—А–Є—В –Є –Љ–∞–Є.
–°–љ–Є–Љ–Ї–Є: Wikimedia/Ithaca/Google
–Т–Є–ґ –Њ—Й–µ: –Ф–Є–љ–Њ–Ј–∞–≤—К—А —Б—А–µ—Й—Г –Ѓ—Б–µ–Є–љ –С–Њ–ї—В –≤ —Б—К—Б—В–µ–Ј–∞–љ–Є–µ, –Ї–Њ–µ—В–Њ –≤—Б–µ–Ї–Є –Є—Б–Ї–∞ –і–∞ –≤–Є–і–Є
–Ю—Й–µ –њ–Њ —В–µ–Љ–∞—В–∞
–Ъ–Њ–Љ–µ–љ—В–∞—А–Є (0)








–Ю—Й–µ –Њ—В HiEnd

–Я—А–µ–њ–Њ—А—К—З–∞–љ–Њ





–Ь–Њ–ґ–µ –Ф–∞ –•–∞—А–µ—Б–∞—В–µ




–Ш–Ј–±—А–∞–љ–Њ –Њ—В —А–µ–і–∞–Ї—В–Њ—А–∞
–°–µ–ї–µ–Ї—Ж–Є—П –Њ—В —Б—В–∞—В–Є–Є –Є —А–µ–≤—О—В–∞ –Њ—В —А–µ–і–∞–Ї—В–Њ—А–Є—В–µ –љ–∞ HiComm




